Python pandasでExcelファイル読み込み(DataFrame形式でデータ取得)
使用データ
csvの時同様e-Statから適当にデータをとってきて使用させていただきます。
国勢調査 / 令和2年国勢調査 / 速報集計 人口速報集計 (男女別人口及び世帯総数)
開くとこの様なデータになっています。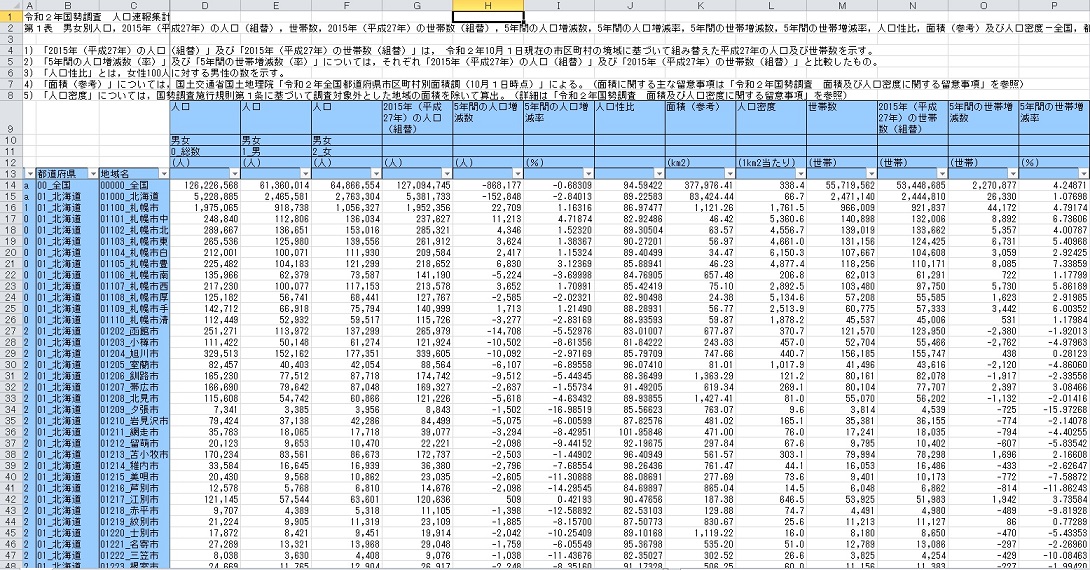
このデータをpandasのread_excel()を使って読み取ってみます。
事前準備
read_excel()は内部ではファイル形式に合わせていくつかのライブラリを使用しています。
engine:str, default NoneIf io is not a buffer or path, this must be set to identify io. Supported engines: “xlrd”, “openpyxl”, “odf”, “pyxlsb”. Engine compatibility :“xlrd” supports old-style Excel files (.xls).“openpyxl” supports newer Excel file formats.“odf” supports OpenDocument file formats (.odf, .ods, .odt).“pyxlsb” supports Binary Excel files.
※公式ドキュメントより引用
大抵の場合.xlsと.xlsxが読み込めればいいと思うので、とりあえずopenpyxlとxlrdをインストールしておけば十分でしょう。
pip install openpyxlpip install xlrd
anacondaを使っている場合は下記などでインストール可能です。
ANACONDA.ORGで検索するといくつかパッケージが見つかります。
conda install -c conda-forge openpyxlconda install -c conda-forge xlrd
基本的な使い方
基本的には引数のioにExcelファイルのパスを指定するだけで読み取りが可能です。
import pandas as pdif __name__ == '__main__':df = pd.read_excel('a01.xlsx')print(df)
今回の場合、読み取ると下記のようになっています。
これだと使いにくいので、色々試していきます。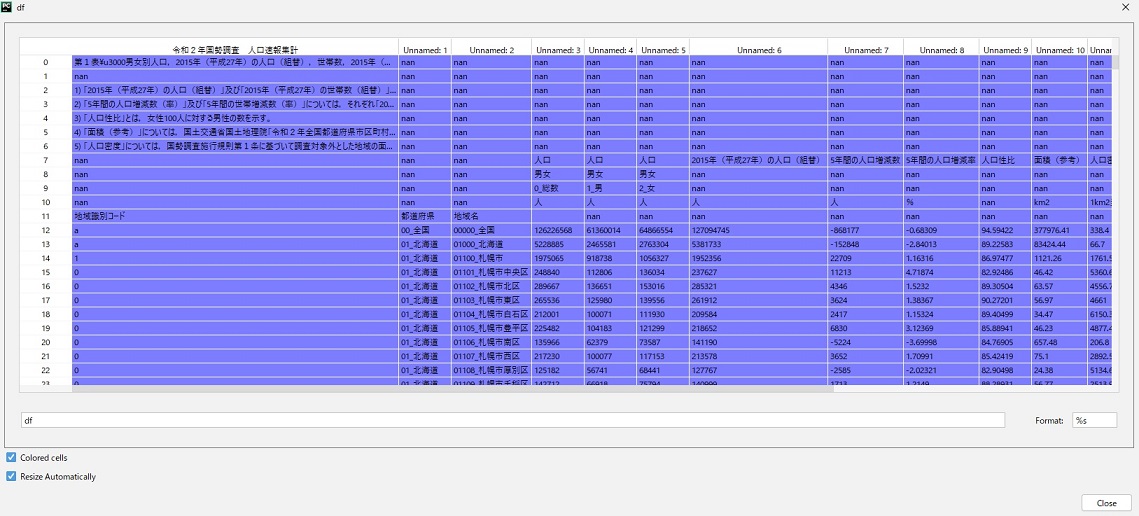
ヘッダー行、インデックス行の指定
引数のheader、index_colに0始まりの行番号、列番号を指定することで、ヘッダー/インデックスとして使用することが出来ます。
また、この2つはリストで指定することが可能です。今回のファイルは少し複雑な構造になっているのでリストで指定してみます。
import pandas as pdif __name__ == '__main__':df = pd.read_excel('a01.xlsx', header=[8,9,10,11,12], index_col=[0,1,2])print(df)
結果は下記のようになります。
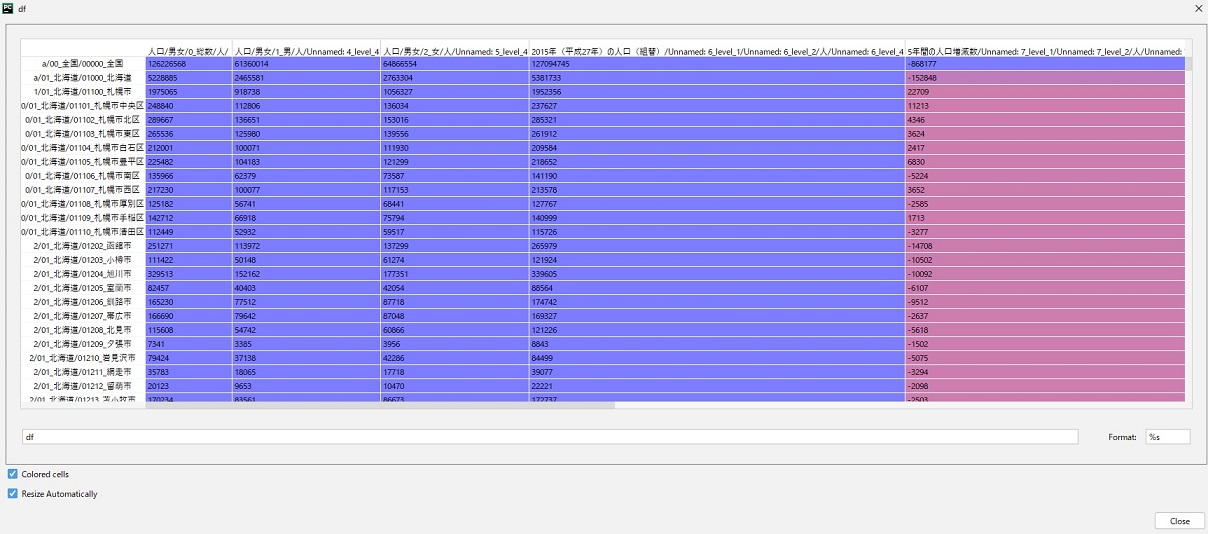
独自のヘッダーを指定
上記の様なデータが扱いにくい場合は、独自のヘッダーを指定することも可能です。
例えば、D、E列に「人口男女総数」「人口男女男」と指定して取得してみます。
import pandas as pdif __name__ == '__main__':df = pd.read_excel('a01.xlsx',names=['人口男女_総数', '人口男女_男'],usecols=[3,4],skiprows=12)print(df)
下記のように取得できます。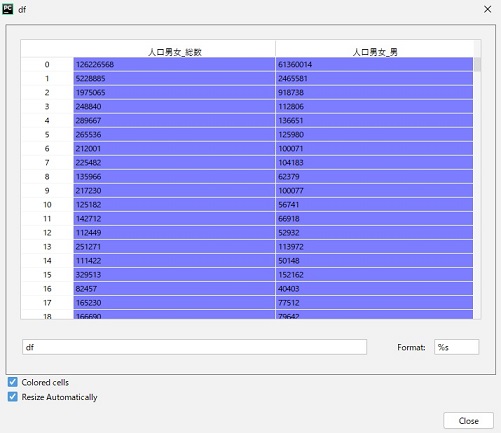
シートの指定
今回のデータはシートが1つしかなかったので指定する必要がありませんでしたが、複数が存在する場合「特定のシートのデータのみ取得」「複数シートのデータを取得」といったことも可能です。 サンプルファイルを用意して試してみます。
■Sheet1
| col0_sheet1 | col1_sheet1 |
|---|---|
| 0 | 3 |
| 1 | 4 |
| 2 | 5 |
■Sheet2
| col0_sheet2 | col1_sheet2 |
|---|---|
| 0 | 3 |
| 1 | 4 |
| 2 | 5 |
import pandas as pdif __name__ == '__main__':# Sheet1データ取得df_sheet1 = pd.read_excel('sample.xlsx', sheet_name='Sheet1')print(df_sheet1)# 出力結果# col0_sheet1 col1_sheet1# 0 0 3# 1 1 4# 2 2 5# Sheet2データ取得df_sheet2 = pd.read_excel('sample.xlsx', sheet_name='Sheet2')print(df_sheet2)# 出力結果# col0_sheet2 col1_sheet2# 0 0 3# 1 1 4# 2 2 5# Sheet1,Sheet2データ取得(シート名で指定)df_sheetall = pd.read_excel('sample.xlsx', sheet_name=['Sheet1','Sheet2'])print(df_sheetall)# 出力結果# {'Sheet1':# col0_sheet1 col1_sheet1# 0 0 3# 1 1 4# 2 2 5,# 'Sheet2':# col0_sheet2 col1_sheet2# 0 0 3# 1 1 4# 2 2 5}# Sheet1,Sheet2データ取得(番号で指定)df_sheetall2 = pd.read_excel('sample.xlsx', sheet_name=[0, 1])print(df_sheetall2)# 出力結果# {'Sheet1':# col0_sheet1 col1_sheet1# 0 0 3# 1 1 4# 2 2 5,# 'Sheet2':# col0_sheet2 col1_sheet2# 0 0 3# 1 1 4# 2 2 5}
複数シートのデータを取得した場合、辞書型で取得することが出来るので、下記の様にDataFrameを取得することが可能です。
import pandas as pdif __name__ == '__main__':# Sheet1,Sheet2データ取得(シート名で指定)df_sheetall = pd.read_excel('sample.xlsx', sheet_name=['Sheet1','Sheet2'])print(df_sheetall)# 出力結果# 上記同様# DataFrame取得df_sheetall_ex = df_sheetall['Sheet1']print(df_sheetall_ex)# 出力結果# col0_sheet1 col1_sheet1# 0 0 3# 1 1 4# 2 2 5# Sheet1,Sheet2データ取得(番号で指定)df_sheetall2 = pd.read_excel('sample.xlsx', sheet_name=[0, 1])print(df_sheetall2)# 出力結果# 上記同様# DataFrame取得df_sheetall2_ex = df_sheetall2[0]print(df_sheetall2_ex)# 出力結果# col0_sheet1 col1_sheet1# 0 0 3# 1 1 4# 2 2 5
