Python pandasでcsvファイル読み込み(DataFrame形式でデータ取得)
使用データ
今回はこちらのデータを使用します。
国勢調査 / 令和2年国勢調査 / 小地域集計 (主な内容:基本単位区別,町丁・字別人口など) 13:東京都
開くとこの様なデータになっています。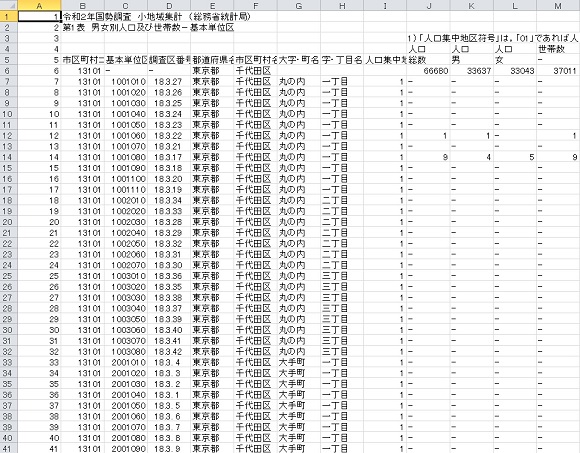
このデータをpandasのread_csv()を使って読み取ってみます。
文字コードの指定
大抵の場合、csvファイルを読み取るだけであれば下記の様にするだけで大丈夫です。
import pandas as pdif __name__ == '__main__':df = pd.read_csv('h01_13.csv')print(df)
しかし、今回は下記の様なエラーが発生します。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x97 in position 0: invalid start byte
公式ドキュメントではデフォルト値=Noneとなっていますが、utf-8で読み取りが行われる様です。
サクラエディタでファイルを開いてみるとSJISとなっています。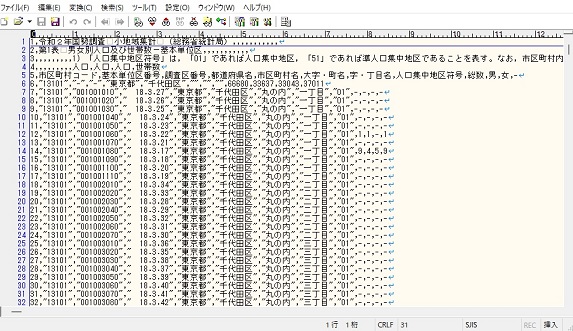
なので、下記のように文字コードを指定して実行してみます。
引数のencodingで指定することが可能です。
import pandas as pdif __name__ == '__main__':df = pd.read_csv('h01_13.csv', encoding="shift-jis")print(df)
エラーなく実行することが出来ました。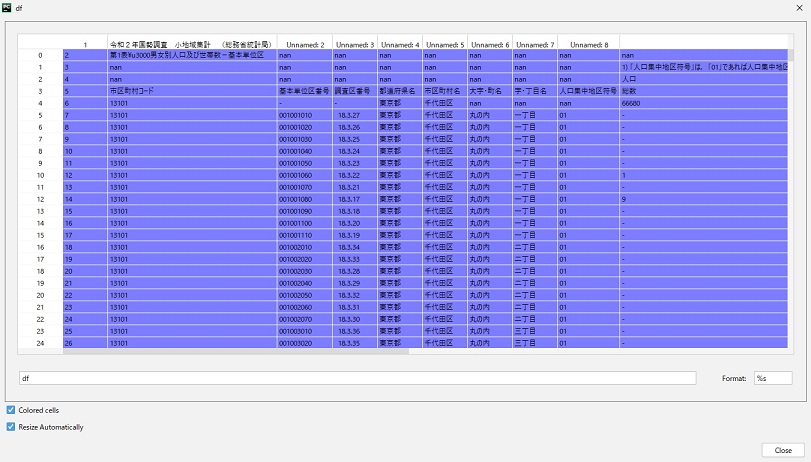
列、開始行を指定
データ処理を行うには、A列、1~4行目はなくても良さそうなので、B~M列、5行目以降のデータを取得してみます。
列の指定はusecols、開始行の指定はskiprowsで指定することが可能です。
usecols:読み込みたい列を指定します。列は0始まりです。
skiprows:指定した行数分スキップしてデータを読み込みます。
import pandas as pdif __name__ == '__main__':df = pd.read_csv('h01_13.csv', skiprows=4, usecols=[1,2,3,4,5,6,7,8,9,10,11,12], encoding="shift-jis")print(df)
下記のように取得できました。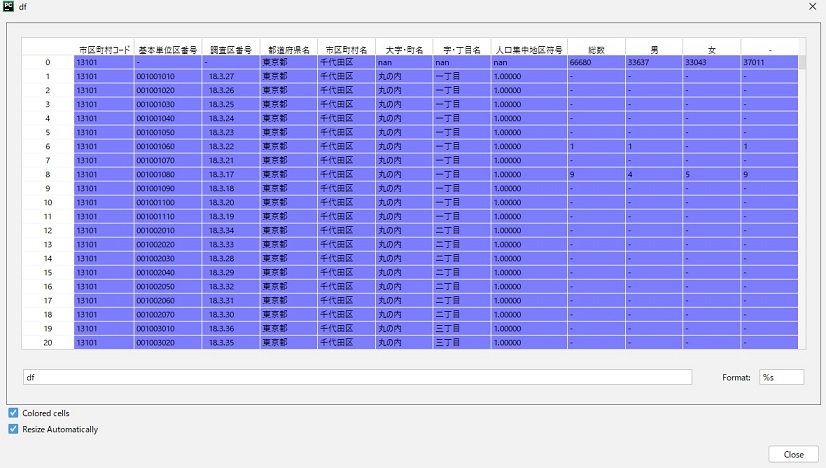
また、usecolの代わりにheaderを使用しても同様の結果を取得することが可能です。
headerは行名(ヘッダー行)として使用する行を指定する引数です。
下記のように5行目をヘッダー行を指定することで同様の結果を取得することが出来ます。
※0始まりのため、5行目を指定する場合はheader=4とする
import pandas as pdif __name__ == '__main__':df = pd.read_csv('h01_13.csv', header=4, usecols=[1,2,3,4,5,6,7,8,9,10,11,12], encoding="shift-jis")print(df)
欠損値として扱う値の指定
DataFrameではdropna()を使用することでnanを含むデータを削除することが出来ます。
そのため、データ読み込み時からあらかじめnanとしてデータを読み取った方が後々楽な場合があります。
pandasではna_valuesで値を指定することで、NaNとしてデータを読み込むことが出来ます。
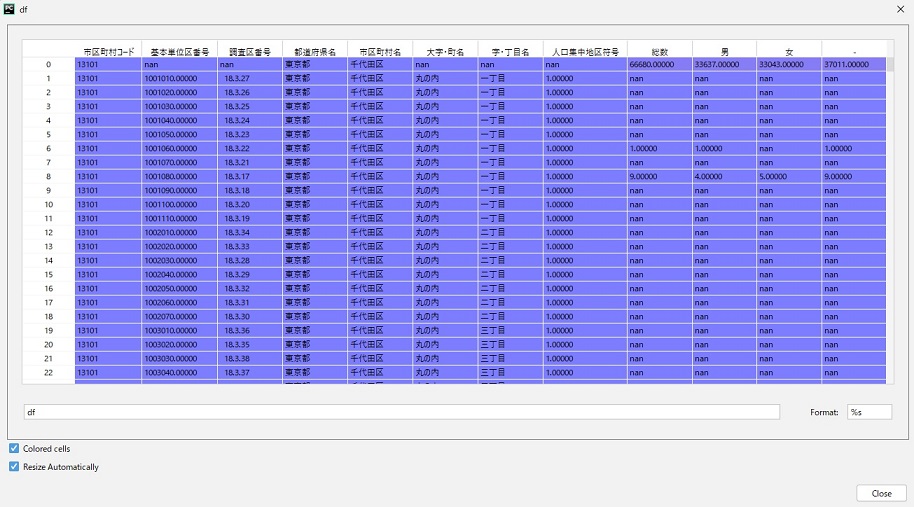
今回は「-」をnanとして読み込んでみます。
import pandas as pdif __name__ == '__main__':df = pd.read_csv('h01_13.csv', skiprows=4, usecols=[1,2,3,4,5,6,7,8,9,10,11,12], encoding="shift-jis")print(df)
行名(ヘッダー行)の指定
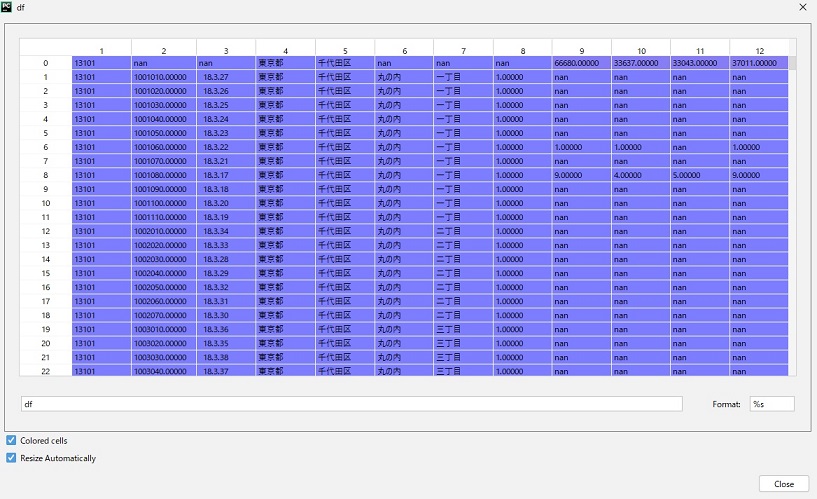
上記の例では先頭行がヘッダーとして使用されていましたが、引数namesで任意の値を指定することでそれをヘッダーすることが出来ます。
これまでは5行目をヘッダー行として使用していたため、skiprows=4としていましたが今回の場合5行目は不要なためskiprows=5としています。
import pandas as pdif __name__ == '__main__':df = pd.read_csv('h01_13.csv',skiprows=5,usecols=[1,2,3,4,5,6,7,8,9,10,11,12],encoding="shift-jis",names=['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12'])print(df)
他にも様々な引数がありますが、よく使用するのは上記のものかなと思います。
その他のものは公式ドキュメントをご参照ください。
